- 跳转类型:
1=首页, 2=内页...
- 用户性别:
1=男, 2=女, 0=未知
- 订单状态:
1=待支付, 2=已支付, 3=已发货, 4.2=已取消
这些场景都可以用 TINYINT 加上应用层的注释或文档来映射,也可以直接使用 ENUM 类型。我们来从多个维度进行详细的分析。
深入分析:ENUM vs. TINYINT
1. 可读性与可维护性
这是两者最直观的区别。
-
ENUM (枚举):
- 优点:具有极高的可读性,是“自描述”的。当您查询数据库时,看到的是
'HomePage' 或 'InternalPage' 这样的字符串,而不是需要查阅文档才能理解的 1 或 2。这对于新加入的开发人员或数据分析师非常友好。
- 缺点:修改枚举列表比较麻烦。每次增加、删除或修改一个枚举值,都需要执行
ALTER TABLE 操作。在大型表上,这是一个高风险且可能耗时的 DDL (数据定义语言) 操作,可能会导致锁表。
-
TINYINT (微整型):
- 优点:非常灵活。如果需要增加一种新的类型,数据库层面无需任何改动。只需要在应用程序的代码(例如,常量定义、配置文件或关联的字典表)中增加一个新的映射关系即可。这使得应用程序的迭代和部署更加敏捷。
- 缺点:可读性差,是“魔法数字 (Magic Numbers)”。如果不借助文档或代码,你无法知道
jump_type = 2 到底代表什么。这增加了维护成本和沟通成本,也容易出错(比如将 2 误写为 22)。
小结:ENUM 赢在可读性和数据本身的清晰度,而 TINYINT 胜在灵活性和对数据库结构的低侵入性。
2. 存储空间与性能
-
存储空间:
ENUM:MySQL 内部存储 ENUM 时非常高效。它并不是直接存储字符串,而是存储每个字符串在其定义列表中的索引号(从1开始)。如果 ENUM 列表有1-255个成员,它会占用1个字节,和 TINYINT 完全一样。如果列表有256-65535个成员,它会占用2个字节,和 SMALLINT 一样。所以,在存储空间上,ENUM 通常和 TINYINT / SMALLINT 相当,甚至可能更优(因为它不会存储无效值)。TINYINT:占用固定的1个字节,可以存储从 -128 到 127(有符号)或 0 到 255(无符号)的整数。
-
性能与索引:
- 内部机制:由于
ENUM 内部存储的是整数索引,MySQL 在进行排序 (ORDER BY) 和分组 (GROUP BY) 操作时,实际上是对这些整数进行操作,效率非常高,与 TINYINT 基本没有差别。
- 连接查询 (
JOIN):当使用 ENUM 字段作为连接键时,其性能也和 TINYINT 相当,因为底层都是整数比较。
- 索引:两者都可以被高效地索引。B-Tree 索引在整数或内部整数表示上工作得都很好。
- 细微差别:
ENUM 在写入时有一个微小的额外开销,因为它需要去查找字符串在定义列表中的索引位置。但在大多数读多写少的应用中,这点开销可以忽略不计。此外,ENUM 类型在排序时,是按照其定义时的顺序排序的,而不是字符串的字母顺序,这有时会带来便利,有时也可能与预期不符(例如 ENUM('High', 'Medium', 'Low') 排序时 High 在 Medium 之前)。
小结:在性能和存储方面,ENUM 和 TINYINT 几乎没有显著差异。不应该基于性能考量来做决策。
3. 数据完整性与约束
ENUM:提供了内置的数据验证机制。你只能插入在 ENUM 定义列表中存在的值。如果试图插入一个无效的值(例如 'SidePage'),MySQL会报错(在非严格模式下可能会插入一个空字符串,但索引为0的特殊错误成员),从而保证了数据的规范性和一致性。TINYINT:没有任何内置的约束。你可以插入任何在 TINYINT 范围内的数字(如 99),即使这个数字在你的业务逻辑中没有任何意义。数据完整性的保障完全依赖于应用层的代码逻辑。
小结:ENUM 在数据完整性方面具有天然的优势,它将约束放在了离数据最近的数据库层。
4. 跨系统/语言的兼容性
ENUM:是 MySQL 的一种特定类型,虽然很多数据库也有类似实现,但它并非 SQL 标准的一部分。如果未来有数据迁移到其他数据库(如 PostgreSQL, SQL Server)的计划,可能会遇到兼容性问题。此外,某些ORM(对象关系映射)框架对 ENUM 的支持可能不如对整数类型的支持完善。TINYINT:是标准的整数类型,在任何数据库和编程语言中都有对应实现,兼容性极佳。
ENUM 中文 vs. 英文
这是一个非常好的问题,涉及到字符集和国际化。
-
存储和性能:
- 无论
ENUM 的成员是中文 '首页' 还是英文 'HomePage',其在数据库内部的存储都是整数索引(1, 2, 3...)。因此,使用中文或英文对存储空间和查询性能没有任何影响。
-
定义和传输:
- 字符集问题:在定义
ENUM('首页', '内页') 时,你需要确保你的数据库连接、客户端以及表定义的字符集是兼容的(通常是 utf8mb4)。如果字符集不一致,可能会导致插入的中文变成乱码或无法识别。
- 可读性:中文
ENUM 对于中文母语的团队来说,可读性无疑是最高的。
- 潜在风险:
- 跨文化协作:如果团队中有不使用中文的开发者,中文
ENUM 会成为沟通障碍。
- 编码问题:在不同的操作系统、终端或代码编辑器中,如果文件编码处理不当,SQL 文件中的中文字符可能会出现问题。
- URL或API参数:在某些场景下,你可能需要将数据库中的值直接用在URL或API参数中。英文(如
home_page)通常比中文(需要URL编码成 %E9%A6%96%E9%A1%B5)更友好。
建议:
- 最佳实践:通常推荐使用有意义的英文小写字符串(例如
home_page, internal_page)作为 ENUM 的成员。它兼顾了可读性、跨文化协作和技术兼容性。
- 退而求其次:如果团队成员固定且都使用中文,并且没有上述编码或API参数的担忧,使用中文
ENUM 在技术上是完全可行的,并且能提供最佳的母语可读性。
总结文章:终极对决——ENUM 与 TINYINT,谁是状态字段的最佳选择?
在数据库设计中,如何优雅地表示有限集合的状态(如订单状态、用户性别、跳转类型)是每个开发者都会面临的选择题。其中,最常见的两个候选者便是 ENUM 和 TINYINT。它们各有拥趸,但现代开发规范更倾向于基于场景做出权衡,而非一刀切。
核心决策矩阵
| 维度 |
ENUM('active', 'inactive') |
TINYINT (1=active, 2=inactive) |
结论 |
| 可读性/自描述性 |
极高。直接看到有意义的字符串。 |
差。依赖文档或代码注释的“魔法数字”。 |
ENUM 胜出 |
| 数据完整性 |
高。数据库层确保值在预设范围内。 |
低。依赖应用层逻辑,可能插入无效值。 |
ENUM 胜出 |
| 灵活性/可维护性 |
低。修改定义需要ALTER TABLE,操作重。 |
高。增删状态无需修改表结构,应用迭代快。 |
TINYINT 胜出 |
| 性能/存储 |
高效。内部存整数索引,空间和性能与TINYINT几乎无异。 |
高效。标准的1字节整数。 |
平手 |
| 跨平台/标准性 |
差。MySQL特定类型,非SQL标准。 |
极高。所有数据库和语言的标准类型。 |
TINYINT 胜出 |
场景化选择建议
-
何时选择 TINYINT?(更被广泛推荐)
- 状态频繁变更或扩展的业务:如果你的业务处于快速迭代期,状态类型未来可能会经常增删。例如,一个电商平台的订单状态,初期可能只有几种,但随着业务发展会增加“拼团中”、“待分享”、“已退款”等多种状态。使用
TINYINT可以避免频繁的ALTER TABLE操作,对持续集成和部署(CI/CD)流程更友好。
- 追求极致的灵活性和解耦:当数据库设计追求与应用逻辑的最大解耦时,
TINYINT是更好的选择。状态的定义和管理完全由应用程序掌握。
- 需要跨数据库迁移或多语言协作:在考虑未来技术栈可能变化或有国际化团队协作时,使用标准的
TINYINT可以避免很多兼容性问题。
使用TINYINT的最佳实践:
- 在应用层建立清晰的常量或枚举类来管理映射关系(如
const ORDER_STATUS_PAID = 2;)。
- 建立一个“字典表”或“配置表”来存储这些状态的描述,方便管理和前端展示。
- 在数据库的字段注释中明确写出每个数字的含义,作为最后的防线。
-
何时选择 ENUM?
- 状态极其稳定且数量极少的场景:当一个字段的状态是固定的、几乎永远不会改变的。例如,
gender 字段的 'Male', 'Female', 'Other';或者记录日志级别的 'DEBUG', 'INFO', 'WARN', 'ERROR'。
- 小型项目或内部工具:在一些敏捷性要求不高、团队内部沟通顺畅的小项目中,
ENUM 的直观性可以提升开发效率。
- 数据完整性要求极高:当绝对不能容忍无效状态值入库,且希望由数据库层面提供强约束时。
关于 ENUM 中使用中文还是英文
- 技术上:使用中文和英文对性能和存储没有影响,因为内部都存为整数。
- 实践上:强烈推荐使用有意义的、小写下划线的英文单词(如
'home_page')。这最大程度地保证了代码的可读性、跨文化团队的协作效率以及与各类工具的兼容性,避免了潜在的字符集和编码问题。
最终结论
在现代大型、快速迭代的互联网项目中,TINYINT 通常是更受推崇、更“政治正确”的选择。它牺牲了数据库的自描述性,换来了无与伦比的灵活性和应用层的敏捷性,这在当今的软件开发实践中往往更为重要。
然而,ENUM 并非一无是处。在状态集稳定不变的简单场景下,它提供的可读性和数据完整性保障依然非常有价值。
因此,理解两者的核心取舍,并结合你的业务稳定性、团队规模、迭代速度来做出明智的选择,才是最佳的开发规范。
那么,为什么是 TINYINT 而不是 SMALLINT 呢?
这是一个非常好的追问,它触及了数据库设计的另一个核心原则:选择最合适、最紧凑的数据类型。
选择 TINYINT 而不是 SMALLINT 主要基于以下三个原因:
1. 范围足够且精准 (Sufficiency and Precision)
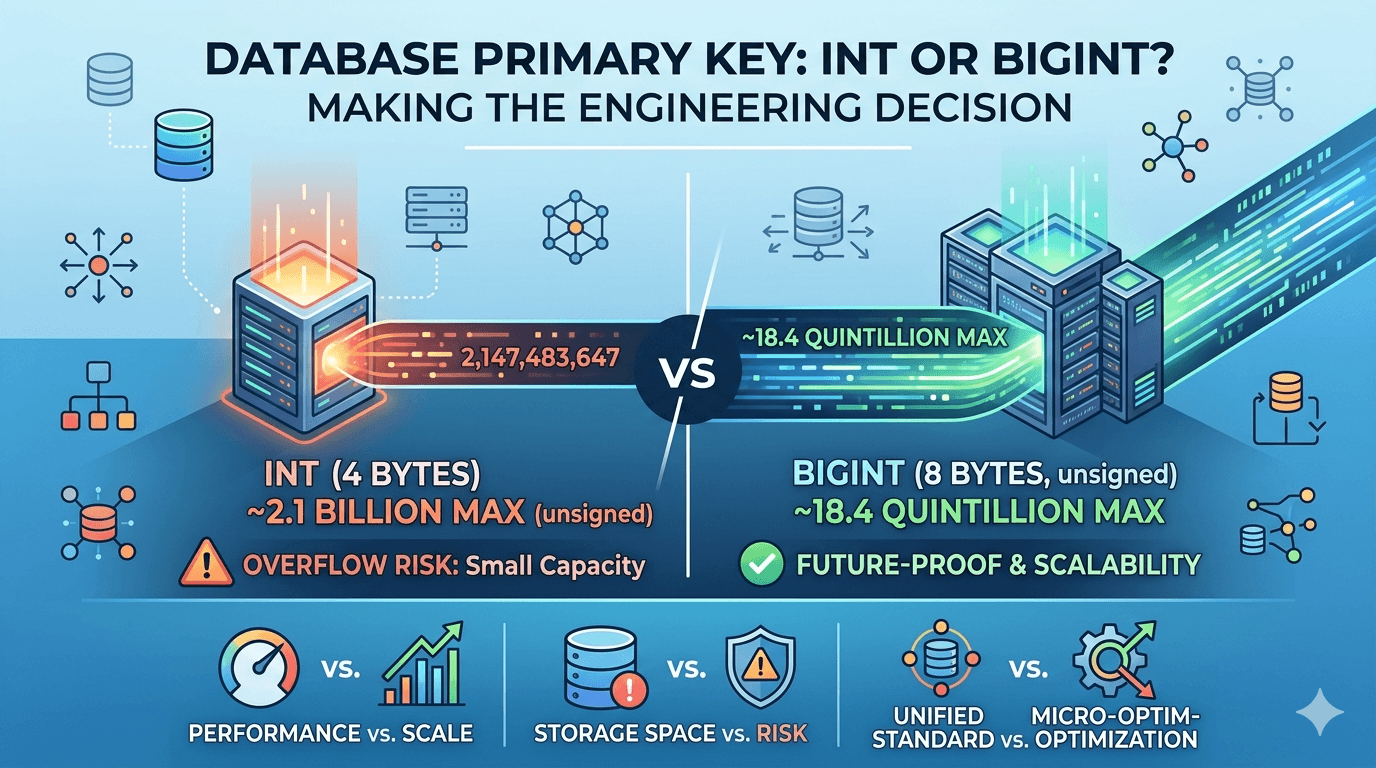
TINYINT (无符号 UNSIGNED) 的取值范围是 0 ~ 255。SMALLINT (无符号 UNSIGNED) 的取值范围是 0 ~ 65,535。
对于我们讨论的“状态”、“类型”这类字段,例如:
- 订单状态:待支付、已支付、已发货、已完成、已取消、退款中... 就算业务再复杂,也很难想象会超过 255 种。
- 用户性别:男、女、未知。3种。
- 跳转类型:首页、内页、商详页、活动页... 几十种了不起了。
- 逻辑开关(是/否):用
TINYINT(1) 表示 0 和 1 即可。
可以看到,TINYINT 提供的 256 个可用“坑位”对于绝大多数这类场景来说绰绰有余。选择 TINYINT 不仅仅是够用,更是向后来的开发者传递了一个明确的信号:这个字段所代表的状态类型,其数量级预计就在几十到一百个之间,不会无限增长。这本身就是一种数据约束和设计意图的体现。
2. 存储空间优化 (Storage Optimization)
TINYINT 占用 1 个字节 (Byte)。SMALLINT 占用 2 个字节 (Bytes)。
虽然每一行只相差 1 个字节,看起来微不足道。但是,在一个设计良好的数据库中,积少成多的效应非常显著:
-
海量数据:假设你有一张用户表或订单表,数据量是 1 亿 行。
- 使用
TINYINT 比 SMALLINT 可以节省:1 亿 * 1 字节 ≈ 95.37 MB 的磁盘空间。
- 如果表上有多个这样的状态字段,节省的空间就会非常可观。
-
内存和缓存:节省的不仅仅是磁盘。当数据被加载到 MySQL 的内存缓存区(如 InnoDB Buffer Pool)中时,更小的数据行意味着在相同大小的内存页中可以存放更多的行数据。这会直接提升缓存命中率,减少磁盘 I/O,从而提高查询性能。
-
网络传输:在数据查询和传输过程中,更小的数据量也意味着更少的网络带宽占用。
3. 遵循数据库设计原则 (Design Principle)
专业的数据库设计遵循“选择能满足需求的最小数据类型”这一黄金法则。这不仅仅是为了节省空间,更是一种严谨和专业的体现。滥用大数据类型(比如用 BIGINT 存年龄,用 VARCHAR(255) 存手机号)是一种坏习惯,它会导致:
结论
因此,选择 TINYINT 而非 SMALLINT 来表示状态,是一个综合了范围精确性、存储和性能优化、以及专业设计规范的明智决策。
当然,如果你的业务场景确实需要超过 255 种分类(例如,一个大型电商平台的商品三级分类ID,其总数可能达到数千上万),那么 SMALLINT 甚至 INT 就成了理所应当的正确选择。归根结底,我们追求的是“恰到好处”的匹配。




 技术随笔
技术随笔